If one of your search terms generated too many items to search for, you will be asked to refine your search. This may occur when using a wildcard (* or ?) on the end of a short search word e.g. ASTM A* or UNS C*. In such a case, please refine your search to make it more accurate, for example, by adding another term, or adding to an existing term, and try again. For example, instead of searching for ' UNS C* ', if you are searching for a copper-nickel, try ' UNS C7* ' and so on.
By default, the word 'a' is defined as a stop word, and will be ignored if it appears in a search term, for example, 27a. In this case, a search for 27a or "27a" will return all records that contain the string '27'. To allow a search for 27a to be performed in this case, it would be necessary to remove the word 'a' from the list of GRANTA MI stop words.
Words defined as stop words will be ignored in search terms. Below is the default list of stop words; additional words can be add to this list by your Granta MI administrator (see the GRANTA MI Administrator's Guide for details on how to do this).
| a | be | into | on | then | was |
| an | but | is | or | there | will |
| and | by | it | such | these | with |
| are | for | no | that | they | |
| as | if | not | the | this | |
| at | in | of | their | to |
Be aware that wildcard searches may not always return the expected results when the search term also includes special characters.
Search in MI:Viewer is implemented with full text search library. It works by adding text from the record — its short and long name, text attribute values, and so on — to a full-text index; queries are then performed on the index, rather than on the records themselves.
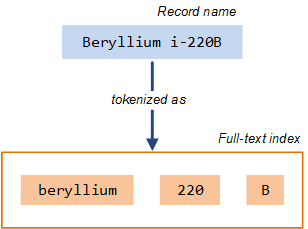
When text is added to the search index, the text is analyzed and split into 'tokens' at alpha-numeric boundaries, at white spaces, at non-alpha-numeric symbols such as hyphens, and so on. Non-alphanumeric characters are treated as a space characters, and common words, such as "a" are removed. These tokens are then stored in the full-text index. For example, here, the record name Beryllium i-220B is indexed into three tokens: ( beryllium, 220, B ).
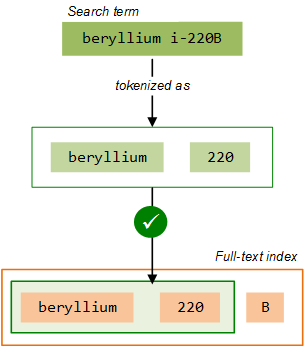
When you enter a search query, the same rules are applied to the text that you enter in order to convert it into a term that can then be matched against the terms in the index; your query text is 'tokenized' at alpha-numeric boundaries, at white spaces, and so on. So the search term beryllium i-220 is converted by the search engine into two tokens, ( beryllium, 220 ), which it then tries to match in the index. This matches two of the tokens in the index for the Beryllium i-220B record, and so the record is returned in the search results:
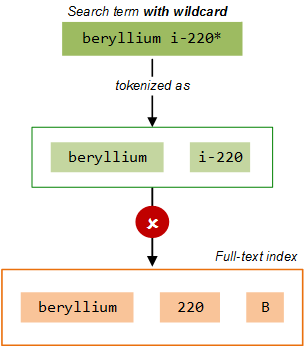
When searching with wild cards, however, different rules for "tokenization" are applied. In this case, the query is split into tokens only at white spaces; common words and special characters are then stripped out. So the wildcard search query beryllium i-220* is tokenized as ( beryllium, i-220 ); this is not a match for the tokens stored in the index for our Beryllium i-220B, record,and so the search will not return the record: